
让AI也懵圈:一次CTF中的对抗样本生成与应用
让AI也懵圈:一次CTF中的对抗样本生成与应用
同步一下推送发的内容
题目来源:GHCTF。感谢GHCTF主办方的师傅们,特别是公开赛道的设置和提供的高质量赛题。
引言
在当前人工智能的应用中,模型通常会基于大量的数据进行训练,以帮助其做出准确的预测。然而,既然是预测,就难免会出现失误。因此,如何确保模型的鲁棒性和安全性成为了一个至关重要的话题。
对抗样本(Adversarial Examples)攻击是AI安全中不可忽视的一个隐患。对抗样本是指通过精心设计,对输入数据进行微小修改,通常这些修改对人眼几乎无法察觉,但却能导致模型产生错误的分类或判断。例如,下图展示了这种情况:最左侧是原始图像,中间是添加的微小扰动,右侧则是生成的对抗样本。模型在识别原始图像时,会返回结果为猫(虽然这个数据集分辨率很低,就姑且当图里是猫吧),但是模型识别对抗样本时,则会将其识别为狗。
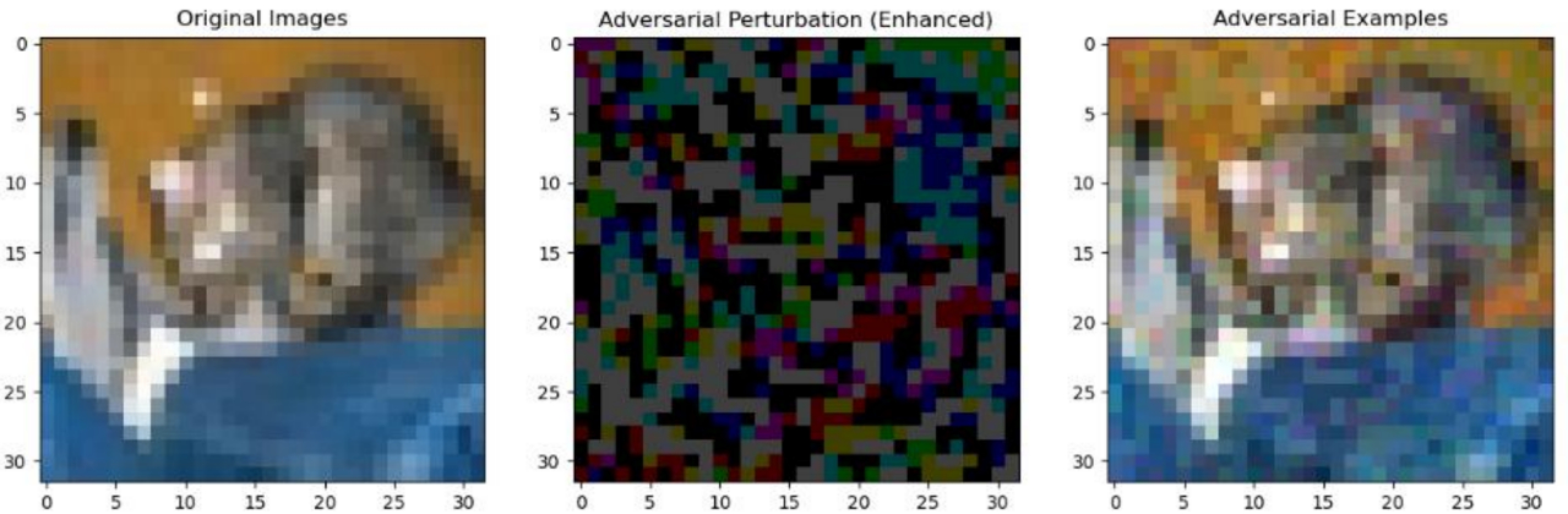
但是这时候就有人要问了,“学长学长,你上面讲的东西还是太抽象,太难理解了,有没有更贴近生活的例子?”
有的兄弟,有的。这样的例子还有两个。
例如新能源汽车的自动驾驶系统,我们都知道,很多新能源汽车的自动驾驶都会依赖于摄像头和传感器来识别路标、行人、其他车辆。但是如果此时攻击者在一个路标上贴上设计好的恶意样本,可能就会导致汽车错误的识别路标,进而做出错误的决策。例如忽视停止信号、错误识别限速路标,可能会造成潜在的交通事故。
当然,对抗样本绝不仅限于对图片的识别,大家日常使用邮箱,一定使用过邮箱中的垃圾邮件功能,通常系统会自动根据关键词、发件人信息等分类邮件是否为垃圾邮件,但是攻击者通过修改邮件内容中特定的词汇或添加一些看似无害的内容,就可能会让原本会被判定为垃圾邮件的邮件成功绕过过滤,从而达到欺骗的目的。
对抗样本
对于对抗样本的生成,通常可以根据攻击方法分为黑盒攻击和白盒攻击两种类型。
黑盒攻击:在黑盒攻击中,攻击者对模型的内部结构一无所知。攻击者只能通过输入数据并观察模型输出结果来获取信息。也就是说,攻击者无法访问模型的权重、结构或任何训练细节。黑盒攻击依赖于对模型输出的反向推断,攻击者通过多次实验来生成有效的对抗样本。
白盒攻击:与黑盒攻击不同,白盒攻击中,攻击者完全了解模型的内部结构和参数,包括权重、梯度信息等。在这种情况下,攻击者能够利用模型的详细信息来精确计算对抗样本,通常能够生成更强的攻击效果。
本次主要关注白盒攻击,后续题目中使用了PGD(投影梯度下降法)算法,下面将简要介绍FGSM和PGD这两种常见的白盒攻击算法,并比较它们的区别。
注:本文不会在算法的实现上过多赘述,如想要进一步资料,请自行查找论文,或私信本文作者。
FGSM
FGSM是最早被提出的对抗样本生成方法之一,它利用梯度信息来快速生成对抗样本。其基本思想是通过沿着损失函数的梯度方向对输入数据进行微小扰动,来“欺骗”模型。在模型在训练过程中,神经网络模型通常会通过最小化损失函数来学习和优化参数,也就是所谓的梯度下降。而对抗样本生成则是在梯度下降的反方向添加一个扰动,以达到使损失函数增大的目的。

其公式如上,其中x_adv也就是扰动,x为原始样本,epsilon是由我们自行设定,最终sign()中的整体则是损失函数关于当前x的梯度。但由于只进行一次扰动更新,生成的对抗样本相对较容易被模型识别,因此对抗性不够强。
PGD
PGD是对FGSM的扩展和改进,它通过多次迭代优化生成对抗样本。PGD使用了与FGSM相同的思想,但与FGSM不同的是,PGD在每次迭代中都进行扰动更新,并且每次迭代之后都会“投影”扰动,使其保持在一定的范围内,确保扰动不会过大。通俗地说,PGD就是小步多次执行的FGSM。
.svg)
PGD的公式如上,其中x_t指的是第t次迭代时的对抗样本;ailpha代表的是每一次更新的步长,此处的ailpha其实就比较像单步执行时的FGSM的epsilon;B则指的是输入空间允许的扰动范围,用于限制扰动的大小;而Proj就是指的投影操作,使得更新后的对抗样本依旧能保持在原始样本的正负epsilon范围内。
CTF题目背景与解题思路
说完了基本的概念,就来看看题目吧,本题目出自FAFU主办的GHCTF的AI部分题目Mortis,出题人:Detective_LFY
题目:【GHCTF】Mortis
题目靶机首页:

(中间省略一堆剧情~)

题目内容中存在一句话:“现在,你的目标就是提供一张图片,让其他粉丝认为这张图仍是Soyo而Mortis小姐认为这是Anon,这样就能证明Mortis小姐不是真正的人类了。”其他粉丝也就是我们,依旧要认为这张图是Soyo也就是扰动不能够添加的太大,而想要让Mortis小姐认为是Anon,也就是需要分类错误。
题目附件中,给了我们预训练好的模型文件,还有题目逻辑的代码,且其中包含了模型的结构,并且是一个二分类模型。模型由三个卷积层(conv1, conv2, conv3)和三个全连接层(fc1, fc2, fc3)组成。每个卷积层后面跟有池化层来减小特征图的尺寸。最终模型会输出一个经过 sigmoid 激活的单一值,也就是会输出一个介于0到1之间的结果,因此是一个二分类模型。
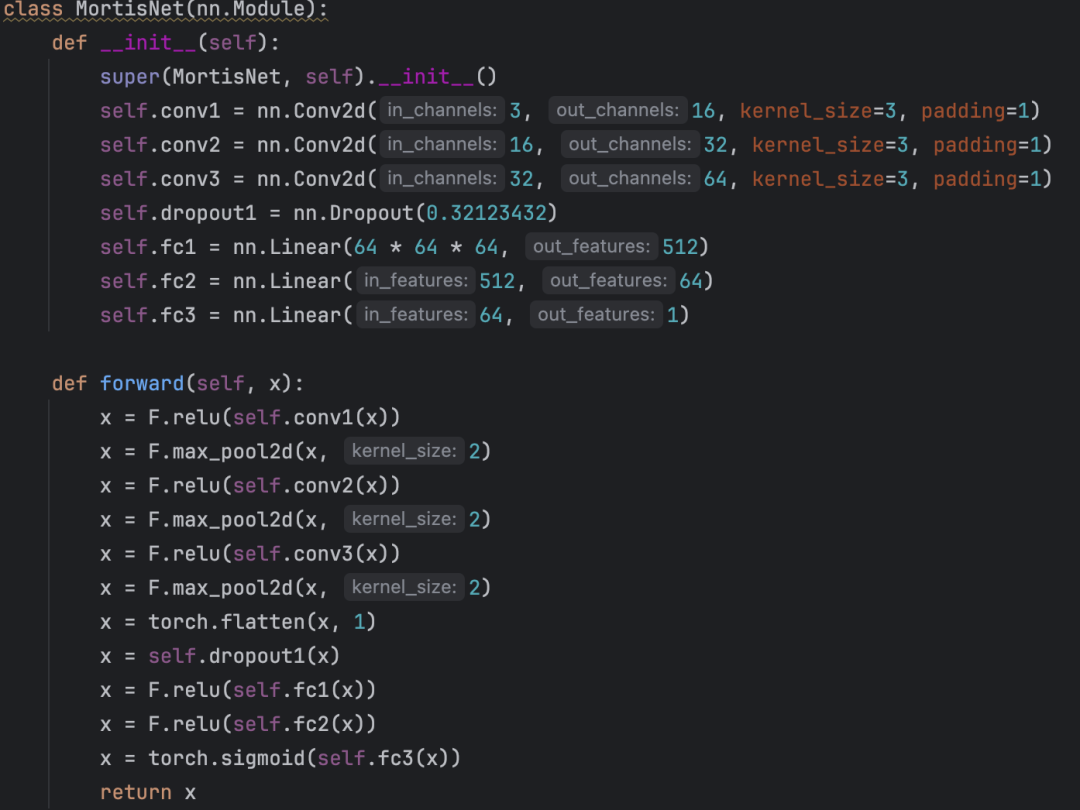
拿到了模型的结构和训练好的模型,是不是就可以联想到前面提到的白盒攻击。那么我们接下来核心需要满足的地方:
我们前面知道输入图像经过模型后,会生成一个介于0到1之间的预测值,可以说是一个置信度。并且题目要求模型输出置信值大于0.9,且psnr大于40,则返回flag。
置信度是指模型对其预测结果的确信程度,通常以0到1之间的数字表示。数字越大,表示模型对预测的结果越有信心。在二分类问题中,如果置信度大于0.9,表示模型几乎确定图像属于某一类别。而PSNR(Peak Signal-to-Noise Ratio,峰值信噪比)是衡量图像质量的指标,表示两幅图像之间的相似度。PSNR值越高,图像差异越小,质量越好。在对抗样本中,PSNR可以用于衡量修改后图像与原图之间的差异,PSNR值高意味着对抗样本对人眼几乎不可察觉。
需要满足PSNR的条件也正是此题的难点之一,也就是说我们在误导模型的同时,还需要确保对原图不能产生过大影响。
关键代码
psnr的计算
.svg)
1 | def calculate_psnr(img1, img2): |
生成对抗样本(让GPT帮忙生成了注释)
1 | def generate_adversarial_example(model, input_tensor, target_confidence, |
使用 PGD算法,通过迭代步骤生成对抗样本。每次迭代时,计算损失函数并反向传播,使用输入张量的梯度符号来生成扰动。通过每次迭代并调整输入图像以确保其在有效范围内,最终得到一个具有所需置信度(0.9)且PSNR值不低于指定阈值(40)的对抗样本时,停止迭代,返回找到的对抗样本。
payload部分截图,需要本题答案附件的同学,请在公众号回复“Mortis对抗攻击答案”。
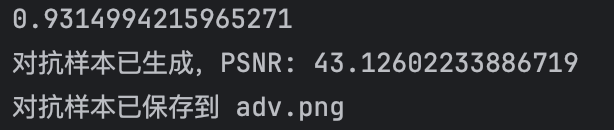
生成的结果:左侧为对抗样本,右侧为原始图像。
可以看到,所生成的对抗样本在肉眼上,与原图无异。
上传对抗样本
成功使用对抗样本误导了模型,再次感谢出题师傅提供的有趣的赛题~
与实际安全防护的关联
目前,防御对抗样本攻击最常见的方式之一就是对抗训练。对抗训练的核心思想是将对抗样本引入到训练过程中,模型不仅要处理正常样本,还要应对经过扰动的对抗样本。通过这种方式,模型在训练时会学习如何在扰动的环境中保持鲁棒性,从而使得模型的决策边界得以优化,增强其抵抗对抗攻击的能力。这样,模型变得不仅仅是在正常数据下表现优秀,还能在面对攻击时依然稳定和准确。
对抗训练与攻击方法
在对抗训练中,PGD(Projected Gradient Descent) 是较为广泛使用的对抗样本生成方法之一。PGD通过不断地调整输入样本的值,逐步逼近模型的决策边界,最终生成强度较大的对抗样本。正因其具有强大的攻击能力,PGD生成的对抗样本在对抗训练中尤为有效。将PGD生成的对抗样本加入训练过程中,不仅能够显著提高模型的鲁棒性,还能帮助模型更好地应对类似的攻击,从而强化防御能力。许多研究和实验也证明了PGD在提升模型对抗能力方面的巨大价值。
然而,除了PGD,还有DeepFool算法,它采用了一种不同的策略。在每次迭代时,DeepFool尽力在各个方向上寻找最小的扰动,直到样本越过决策边界为止。虽然DeepFool生成的扰动相对较小,这意味着生成的对抗样本更加微妙、隐蔽,但也因此在某些情况下,这种方法生成的对抗样本可能无法充分挑战模型的防御能力,特别是当模型已经对较大扰动具备一定鲁棒性时。事实上,在我个人的毕业设计中,我也通过对比实验验证过,结果表明,PGD生成的对抗样本对于对抗训练的效果要显著优于DeepFool,猜测是因为DeepFool算法生成的样本本身就处于决策边界附近,不能够很好的帮助模型很好的进行边界的调整。
有兴趣的同学可以查阅相关资料,深入了解这些对抗样本生成方法及其在对抗训练中的应用。
最后
通过此次遇到的赛题,与大家分享下对抗样本的概念,希望大家能够在不断的学习中找到自己喜欢的领域,并且能够持之以恒的学习和实践 。